Youtube SEO Keyword Generator
Understanding SEO Keywords
SEO (Search Engine Optimization) keywords are specific words and phrases that users employ in search engines. These keywords help platforms like YouTube understand and categorize your content effectively.
Key Characteristics
- 📌 User intent matching
- 📌 Search volume optimization
- 📌 Content relevance indicators
Example: For "How to Cook Pasta" video
✅ Primary keywords: "pasta cooking tutorial", "beginner pasta recipe"
✅ Secondary keywords: "Italian cuisine basics", "kitchen essentials"Strategic Applications of SEO Keywords
Enhanced Video Discovery 📈
Optimized keywords improve search rankings and visibility:
- Case Study: Fitness channel using "home workout routines" increased impressions by 240%
- Implementation: Title, description, and tags optimization
Audience Targeting System 🎯
Keyword Strategy for Tech Reviews:
1. Primary: "gaming laptop comparison 2024"
2. Secondary: "best budget gaming rig"
3. Long-tail: "RTX 4080 vs AMD 7900 performance"Watch Time Optimization ⏳
- Algorithm-friendly metadata
- Suggested videos integration
- Session watch time boosting
Revenue Generation Strategies
Ad Revenue Optimization 💰
- Commercial intent keywords (e.g., "best DSLR camera under $1000")
- Brand partnership opportunities
- CPM rate improvements
Affiliate Marketing Integration
Effective Product Review Structure:
1. Problem statement: "Need affordable video editing setup"
2. Solution: "Best budget equipment roundup"
3. Keywords: "affordable streaming gear", "content creation essentials"Enterprise-Level Applications
Multi-Channel Optimization
- ✅ Digital Marketing Agencies - SEO-driven content strategies
- ✅ E-commerce Brands - Product demo optimization
- ✅ Local Businesses - Geo-targeted keywords (e.g., "NYC coffee shop reviews")
Competitor Analysis Framework 🔍
- Trend identification tools
- Keyword gap analysis
- Content refresh automation
Trend Adaptation Example:
Tracking keyword: "AI content creation tools"
→ Create "Top 10 AI Tools for YouTubers 2024"
→ Optimize with trending sub-keywordsEmerging Trends in Video SEO
AI-Powered Optimization
- Automated transcript analysis
- Predictive keyword scoring
- Multilingual SEO adaptation
Advanced Analytics Integration
Next-Gen Metrics:
- Audience retention correlation
- Keyword performance heatmaps
- ROI prediction modelsYouTube SEO Keyword Generator with Local LLM
Automated SEO keyword extraction using YouTube transcripts and locally hosted Llama3.2-vision model
Pre-Requisites
Required Python packages:
- streamlit:
pip install streamlit - yt-dlp:
pip install yt-dlp - langchain-ollama:
pip install langchain-ollama - langchain-core:
pip install langchain-core
Additional requirements:
- Ollama server running with llama3.2-vision:11b model
- Stable internet connection for YouTube access
System Architecture
The application implements a multi-stage processing pipeline:
- Video Metadata Extraction: YouTube video info and thumbnail retrieval
- Transcript Processing: Automatic subtitle extraction and chunking
- LLM Integration: Local Llama3.2-vision model for text analysis
- Keyword Generation: Two-stage SEO keyword extraction and refinement
Key Components Explained
1. Video Data Fetcher
def fetch_video_data_with_ytdlp(video_url):
ydl_opts = {
"writesubtitles": True,
"subtitleslangs": ["en"]
}
# Metadata and transcript extraction logicHandles YouTube API interactions and subtitle retrieval.
2. Transcript Processor
def split_transcript(transcript, chunk_size=50000):
return [transcript[i:i+chunk_size] for i in range(0, len(...))]Manages large transcripts through chunking for LLM compatibility.
3. LLM Q&A Chain
qna_chain = template | llm | StrOutputParser()
def ask_llm(context, question):
return qna_chain.invoke(...)Orchestrates the prompt engineering and LLM response generation.
User Interface Components
1. Video Input Section
url = st.text_input("Enter YouTube Video URL:")
if url:
thumbnail = fetch_video_thumbnail(url)
st.image(thumbnail)URL input with automatic thumbnail preview.
2. Processing Controls
if st.button("Generate Keywords"):
# Data fetching and processing logic
st.spinner("Fetching video data...")Interactive controls with status indicators.
3. Results Display
st.write("### Generated Keywords:")
st.write(combined_keywords)
st.write("### LLM Refined SEO Keywords:")Multi-stage results presentation with formatted output.
Complete Implementation: youtube_seo_keyword_generator.py
"""
Copyright (c) 2025 AI Leader X (aileaderx.com). All Rights Reserved.
This software is the property of AI Leader X. Unauthorized copying, distribution,
or modification of this software, via any medium, is strictly prohibited without
prior written permission. For inquiries, visit https://aileaderx.com
"""
import streamlit as st
import yt_dlp
from langchain_ollama import ChatOllama
from langchain_core.prompts import (
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
ChatPromptTemplate,
)
from langchain_core.output_parsers import StrOutputParser
# Initialize ChatOllama LLM with base URL and model
base_url = "http://127.0.0.1:11434"
model = "llama3.2-vision:11b"
llm = ChatOllama(base_url=base_url, model=model)
# Set up the prompt templates for the Q&A chain
system_prompt = SystemMessagePromptTemplate.from_template(
"You are a helpful AI assistant who answers user questions based on the provided context."
)
user_prompt = HumanMessagePromptTemplate.from_template(
"""Answer the user's question based on the provided context ONLY! If you do not know the answer, just say "I don't know".
### Context:
{context}
### Question:
{question}
### Answer:"""
)
# Combine system and user prompts into a chat template
messages = [system_prompt, user_prompt]
template = ChatPromptTemplate(messages)
# Create a Q&A processing chain combining the prompt, LLM, and output parser
qna_chain = template | llm | StrOutputParser()
# Streamlit UI setup
st.title("YouTube SEO Keyword Generator")
st.write("Enter a YouTube video URL to generate SEO keywords based on the video transcript.")
# Input field for YouTube video URL
url = st.text_input("Enter YouTube Video URL:")
# Function to fetch the video thumbnail using yt_dlp
def fetch_video_thumbnail(video_url):
"""Fetches the video thumbnail URL using yt_dlp."""
ydl_opts = {
"quiet": True,
"skip_download": True,
}
with yt_dlp.YoutubeDL(ydl_opts) as ydl:
info = ydl.extract_info(video_url, download=False)
return info.get("thumbnail", "")
# Display the video thumbnail if a URL is provided
if url:
with st.spinner("Fetching video thumbnail..."):
thumbnail = fetch_video_thumbnail(url)
if thumbnail:
st.image(thumbnail, caption="Video Thumbnail", use_container_width=True)
# Function to fetch video metadata and transcript using yt_dlp
def fetch_video_data_with_ytdlp(video_url):
"""
Fetches video metadata and transcript using yt_dlp.
"""
ydl_opts = {
"quiet": True,
"skip_download": True,
"format": "bestaudio/best",
"writesubtitles": True,
"writeautomaticsub": True,
"subtitleslangs": ["en"],
}
with yt_dlp.YoutubeDL(ydl_opts) as ydl:
info = ydl.extract_info(video_url, download=False)
title = info.get("title", "Unknown Title")
description = info.get("description", "No Description")
subtitles = info.get("requested_subtitles", {})
transcript = None
if subtitles:
subtitle_url = subtitles.get("en", {}).get("url")
if subtitle_url:
transcript = ydl.urlopen(subtitle_url).read().decode("utf-8")
return title, description, transcript
# Function to split the transcript into smaller chunks
def split_transcript(transcript, chunk_size=50000):
"""Splits the transcript into chunks."""
return [transcript[i:i + chunk_size] for i in range(0, len(transcript), chunk_size)]
# Function to send context and question to the LLM
def ask_llm(context, question):
"""Asks the LLM a question using the provided context."""
return qna_chain.invoke({"context": context, "question": question})
# Button to generate SEO keywords
if st.button("Generate Keywords"):
try:
if not url:
st.warning("Please enter a YouTube video URL.")
else:
# Fetch video metadata and transcript
with st.spinner("Fetching video data..."):
title, description, transcript = fetch_video_data_with_ytdlp(url)
# If transcript is available, split it into chunks
if transcript:
transcript_chunks = split_transcript(transcript)
else:
transcript_chunks = ["No transcript available."]
st.success("Video data fetched successfully!")
st.write(f"**Title:** {title}")
st.write(f"**Description:** {description}")
st.write(f"**Number of transcript chunks:** {len(transcript_chunks)}")
# Generate SEO keywords from the video content
question_keywords = """
You are an assistant for generating SEO keywords for YouTube.
Please generate a list of keywords from the above context.
You can use your creativity and correct spelling if it is needed.
"""
keywords = []
for i, chunk in enumerate(transcript_chunks):
context = f"Title: {title}\nDescription: {description}\nTranscript Chunk {i+1}: {chunk}"
kws = ask_llm(context=context, question=question_keywords)
keywords.append(kws)
# Combine and display generated keywords
combined_keywords = ", ".join(keywords)
st.write("### Generated Keywords:")
st.write(combined_keywords)
# Refine the list of keywords using LLM
question_refine = """
Above context is the list of relevant keywords for a YouTube video.
You need to generate SEO Keywords for it.
"""
with st.spinner("Refining SEO keywords..."):
refined_keywords = ask_llm(context=combined_keywords, question=question_refine)
st.write("### LLM Refined SEO Keywords:")
st.write(refined_keywords)
except Exception as e:
st.error(f"An error occurred: {e}")
Running the Application
streamlit run youtube_seo_keyword_generator.pyAccess the interface at:
- Local URL: http://localhost:8501
- Network URL: http://[your-ip]:8501
Required services:
- Ollama server running on port 11434
- Active internet connection for YouTube access
Conclusion
This application demonstrates an advanced integration of video content analysis and local LLM processing for SEO optimization. Key features include:
Core Capabilities
- Automated Video Processing: Direct YouTube integration for metadata and transcript extraction
- Local AI Processing: Privacy-focused analysis using locally hosted Llama3.2-vision model
- Two-Stage Keyword Generation: Initial extraction followed by LLM refinement
Future Enhancements
- Multi-language subtitle support
- Competitor video analysis integration
- Automated search volume analysis
- Video content summarization features
The system provides content creators with a powerful tool for enhancing video discoverability while maintaining complete data privacy through local processing.
Sequence Flow of Youtube SEO Keyword Generator
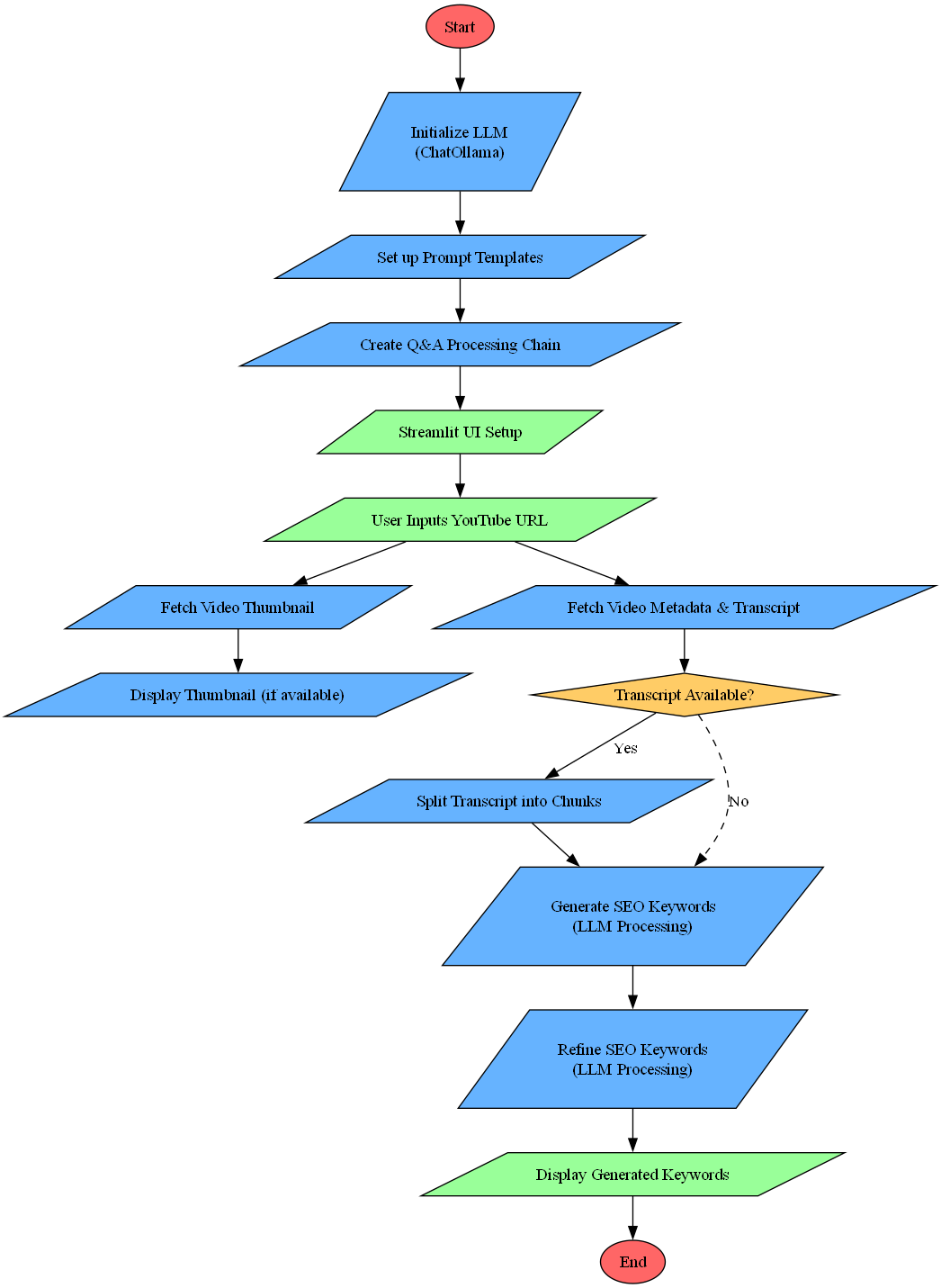
Youtube SEO Keyword Generator Output - 1
Youtube SEO Keyword Generator Output - 2
Youtube SEO Keyword Generator Output - 3
Reference Links
- Streamlit: Streamlit Official Site
- yt-dlp (YouTube Video Data Extraction): yt-dlp GitHub Repository
- Ollama Installation on Local Host: Ollama GitHub Repository
- Running Llama 3.2 on Local Host using Ollama: Ollama Llama3 Library
- LangChain Prompt Templates: LangChain Prompt Documentation
- LangChain Output Parsers: LangChain Output Parsers Guide
- LangChain Chat Models: LangChain Ollama Chat Models
- Regular Expressions for Text Processing: Python Regex Documentation